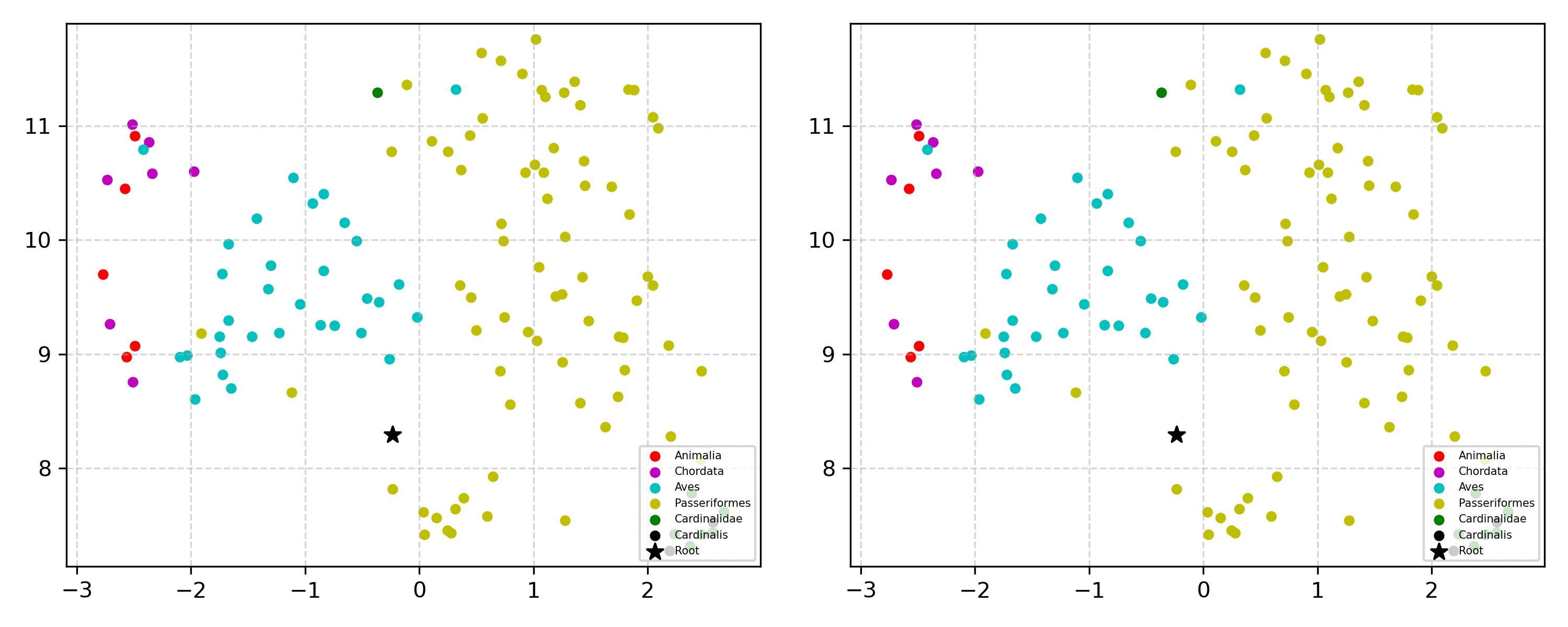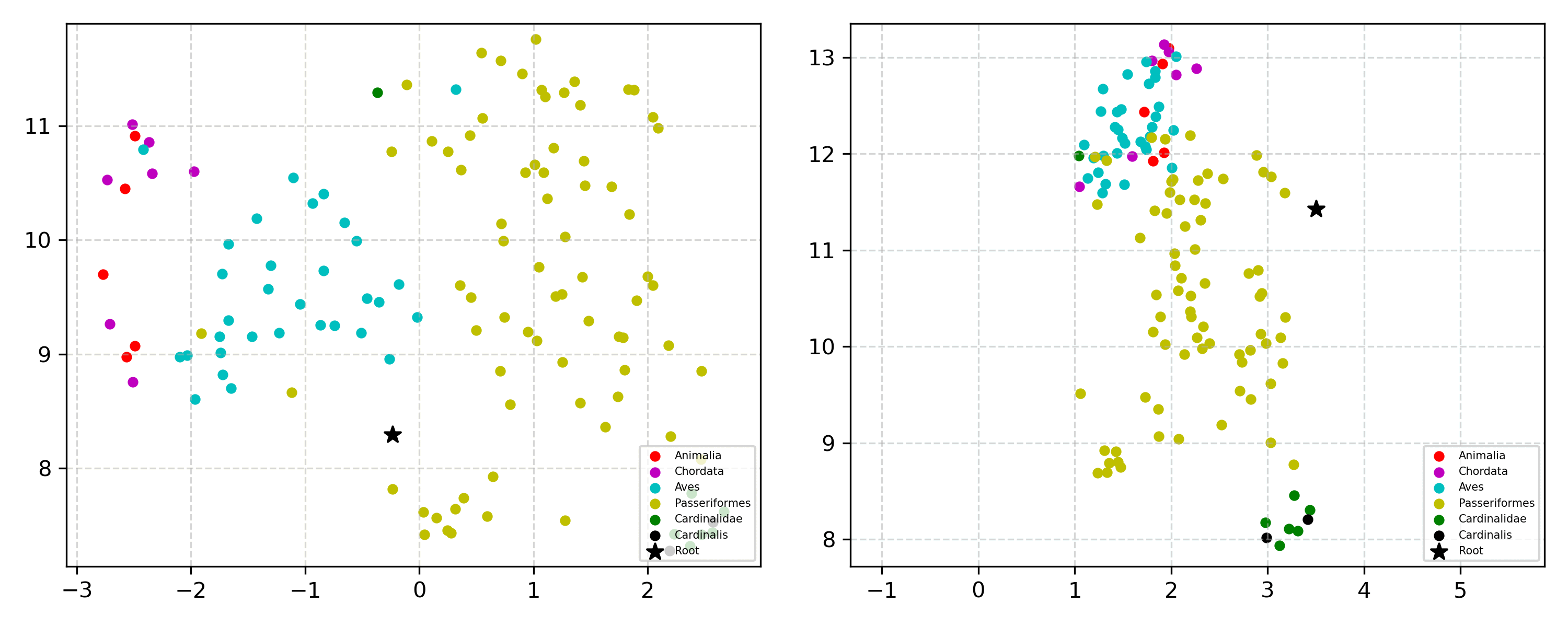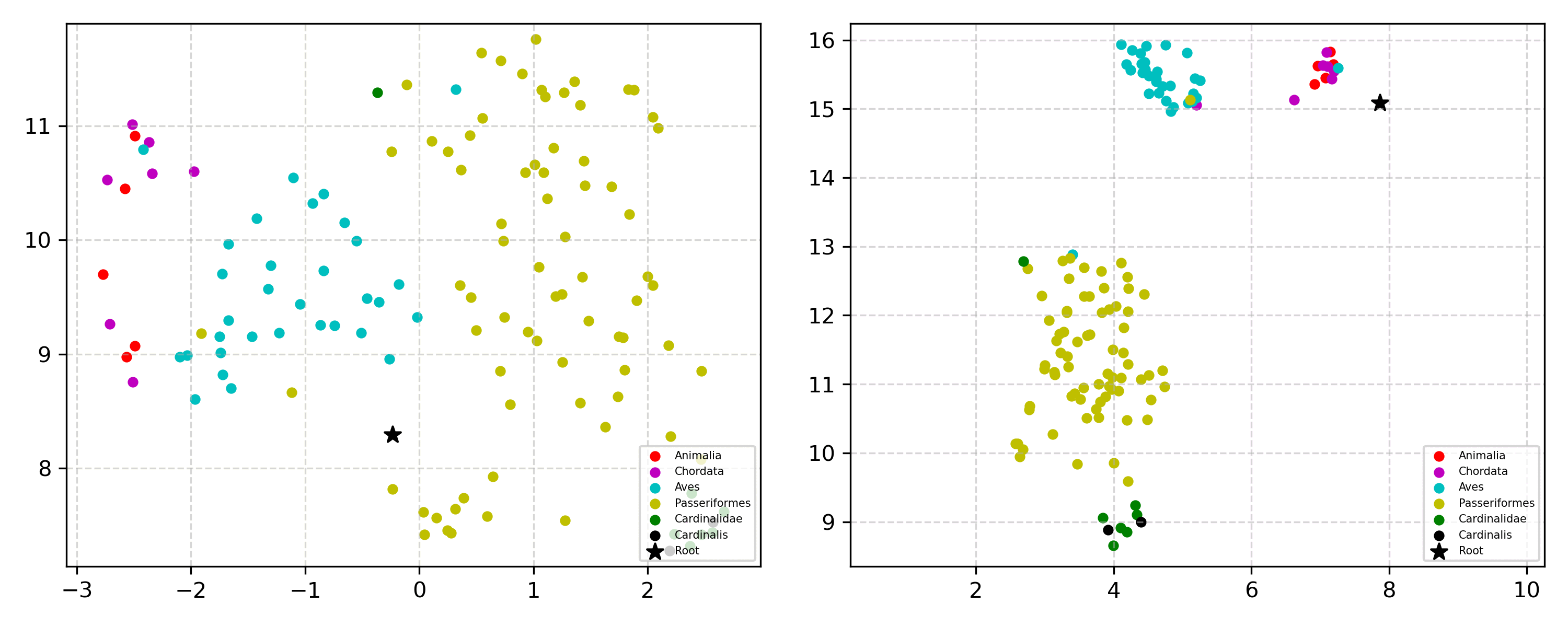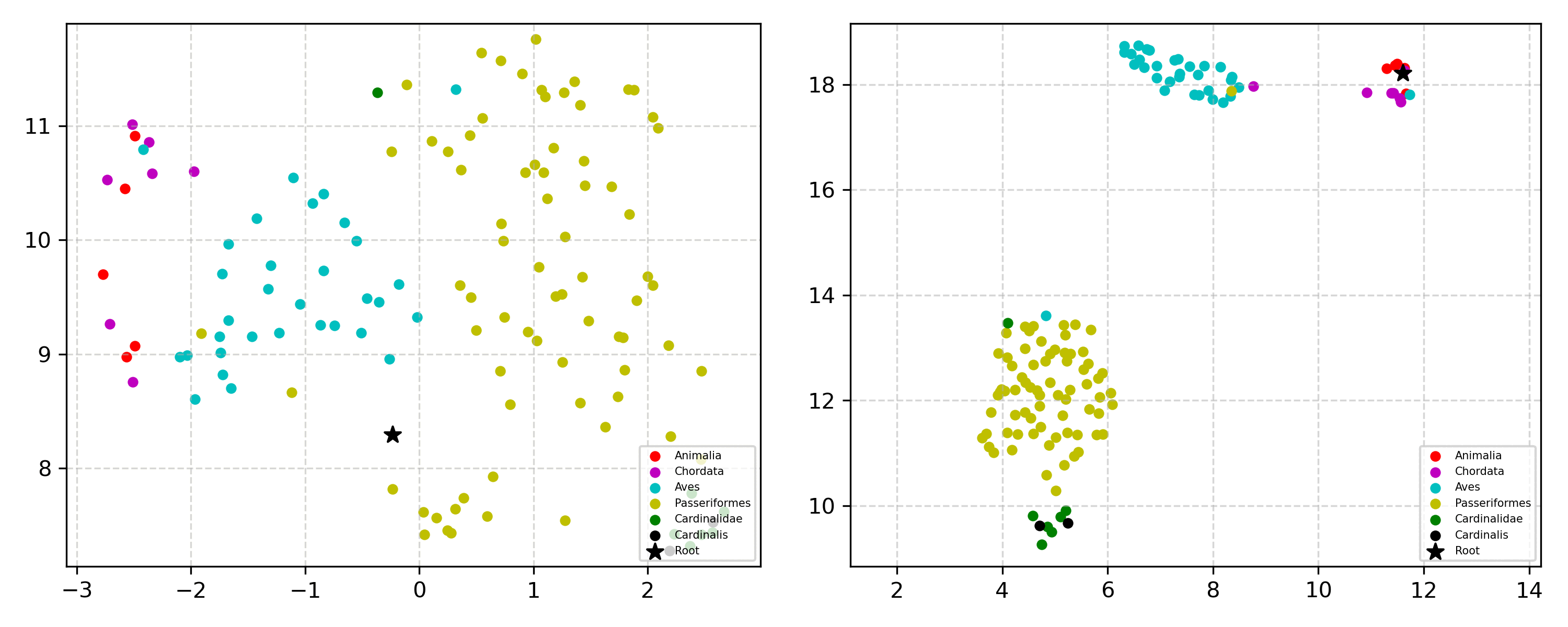
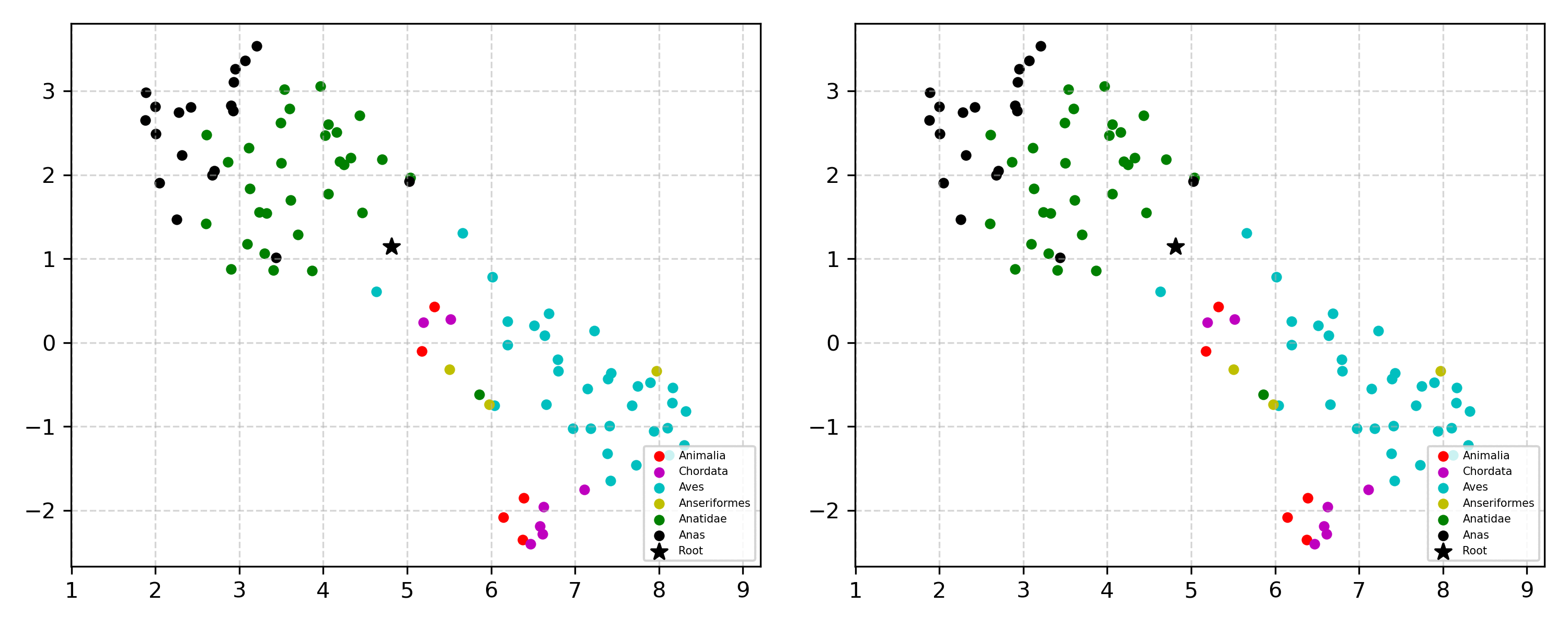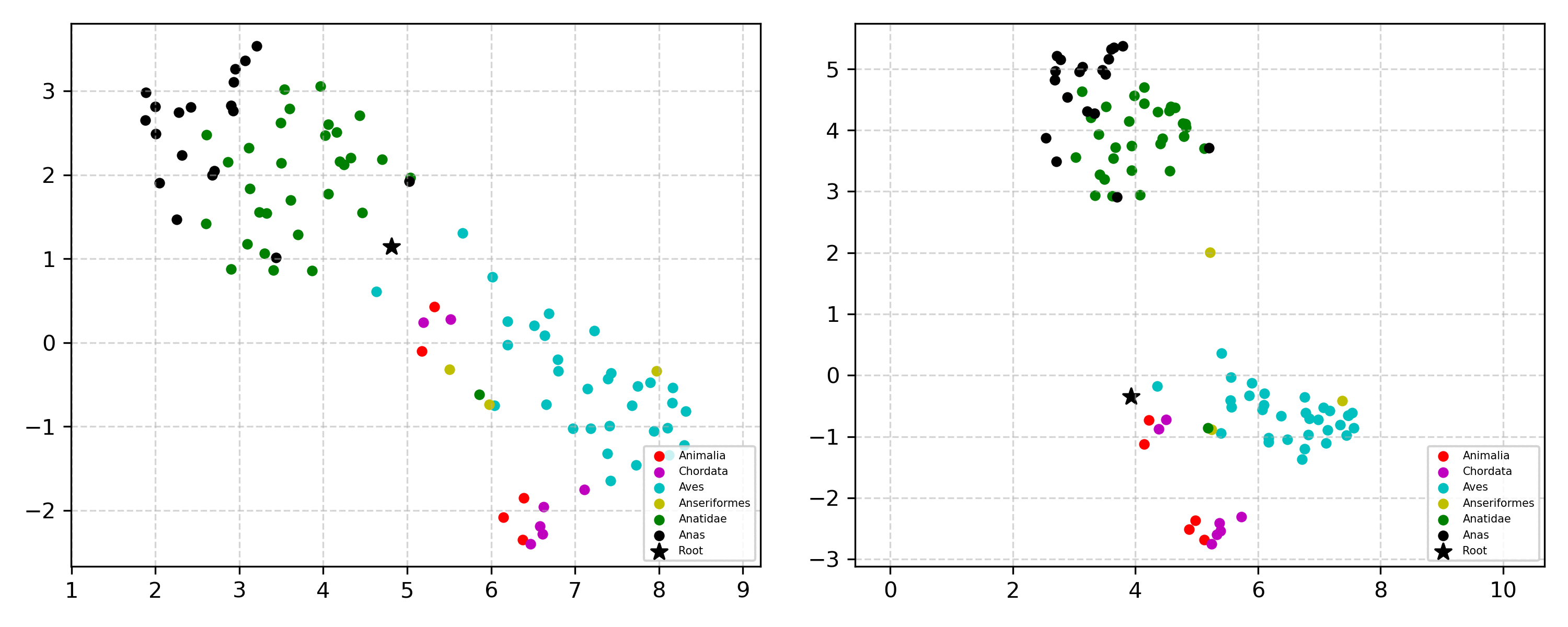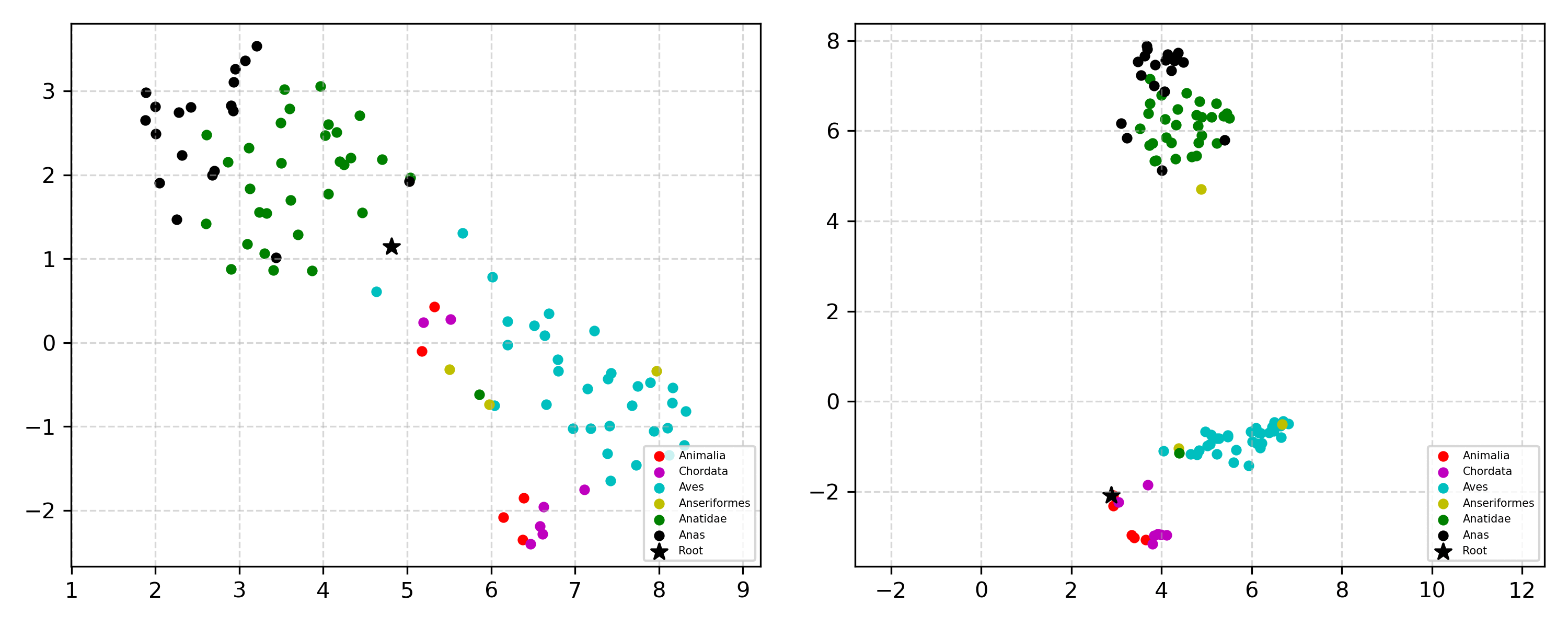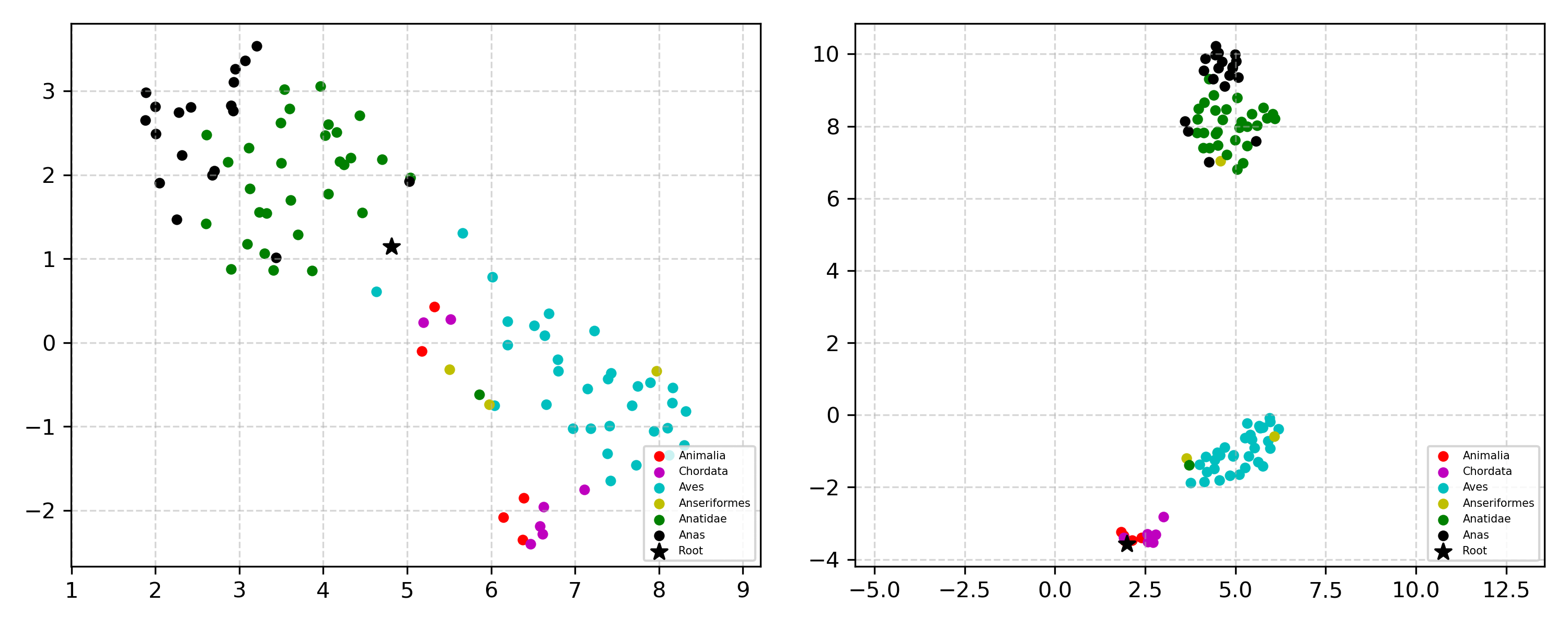
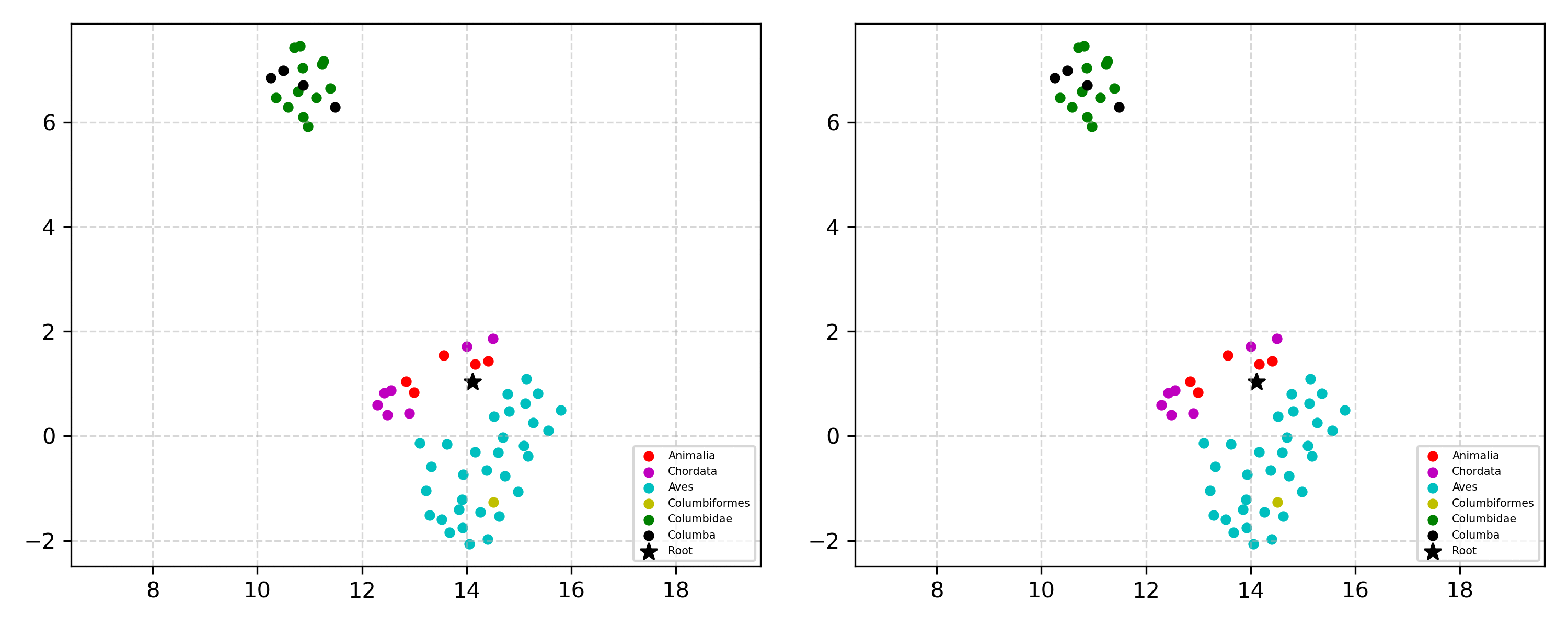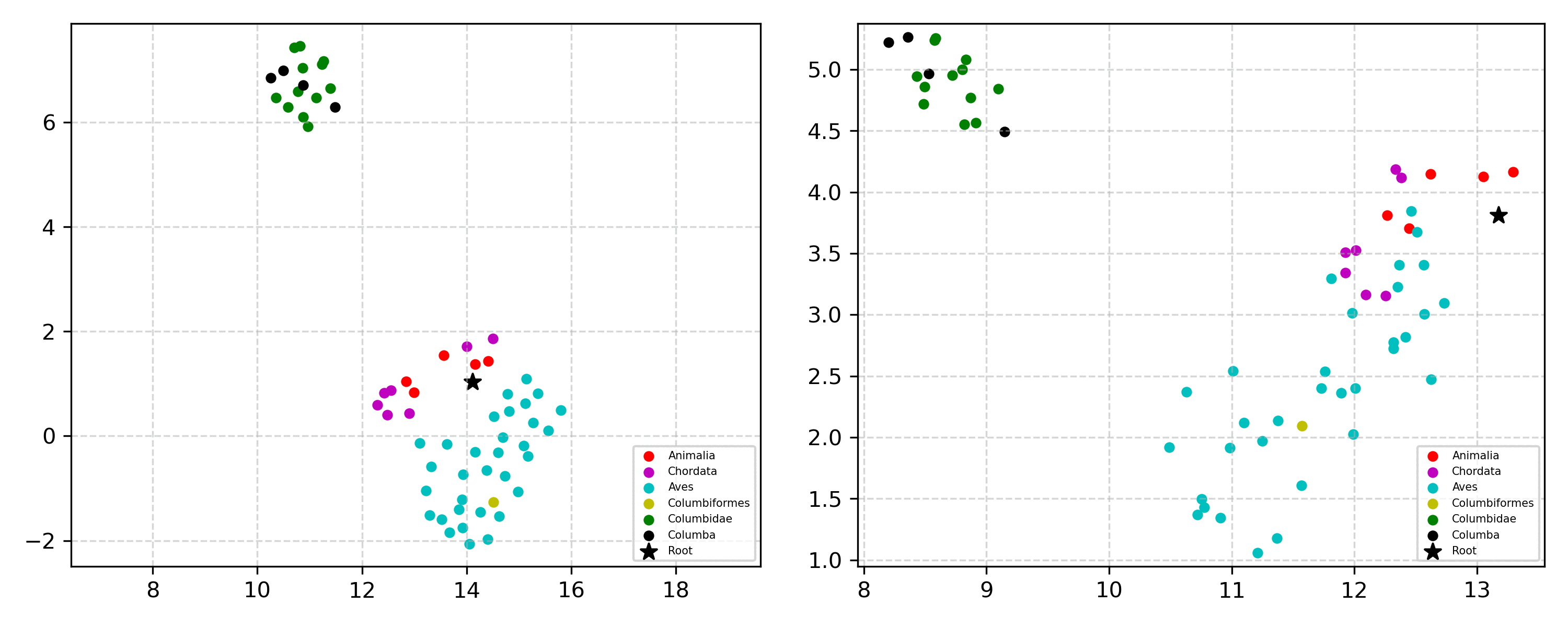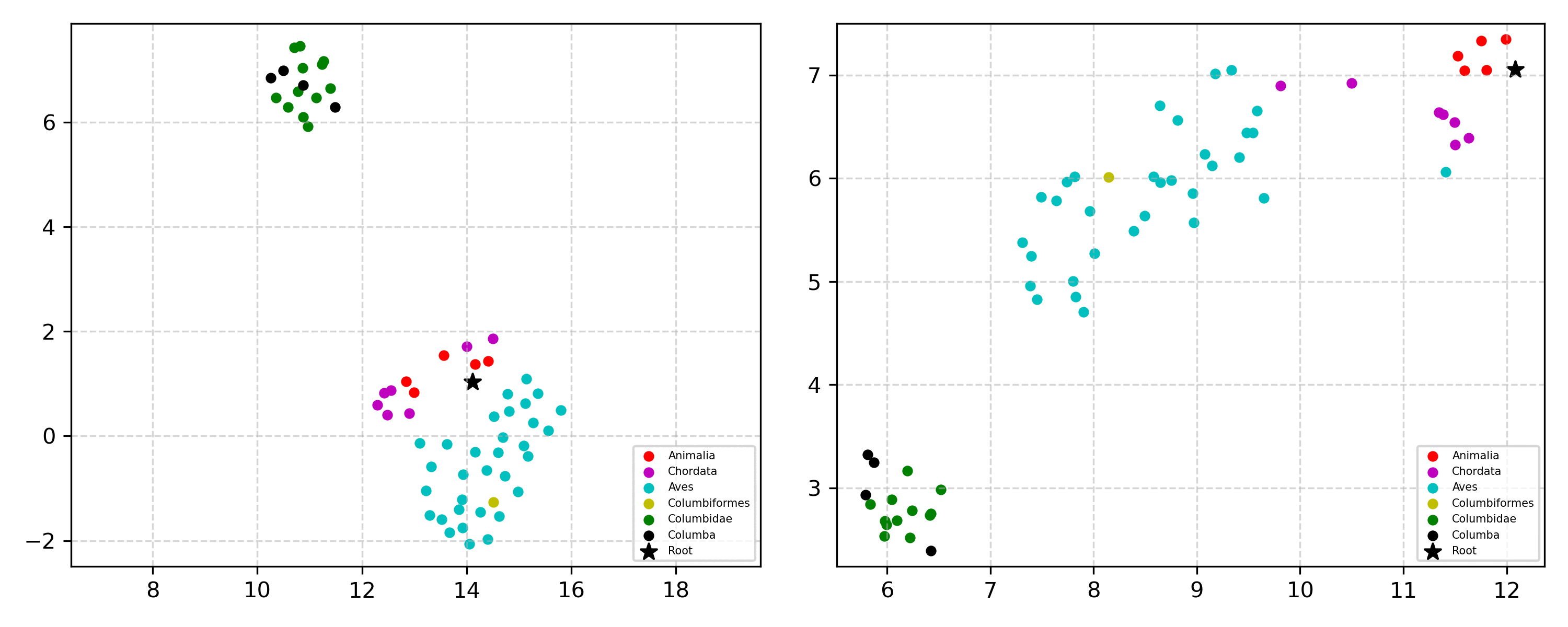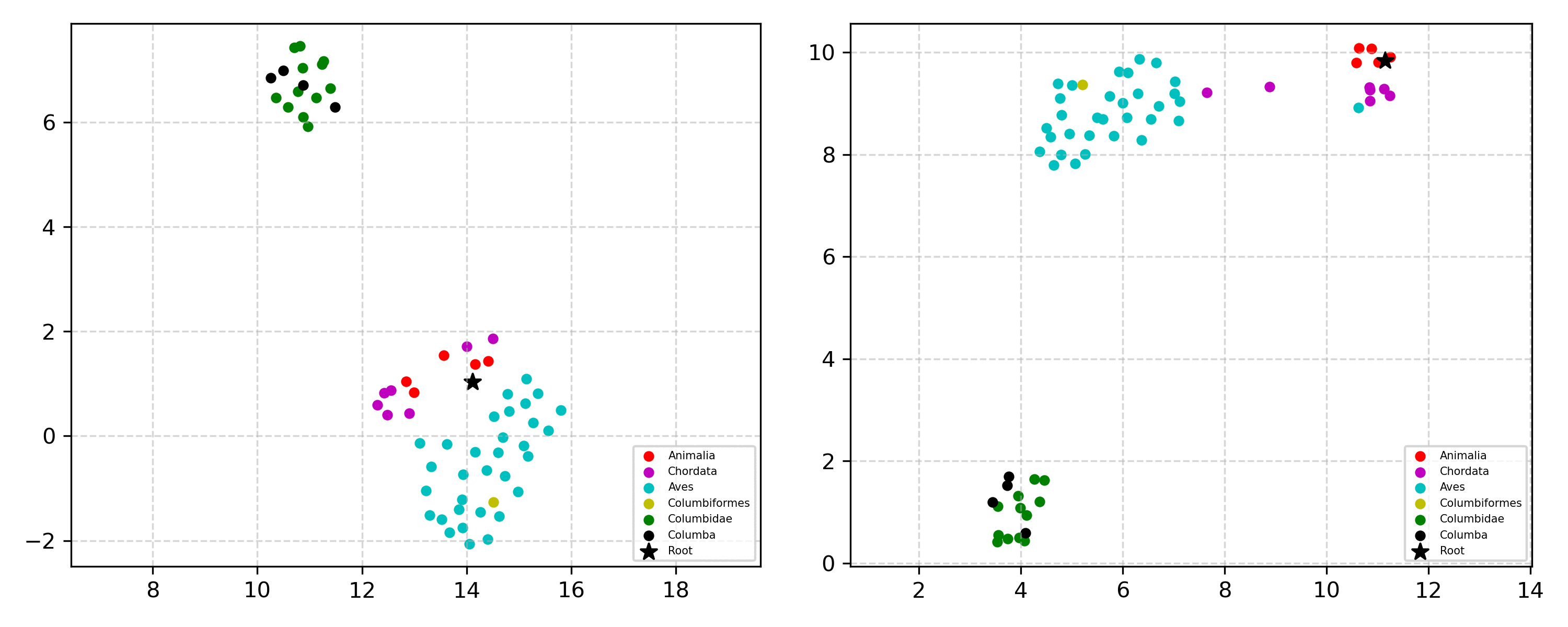
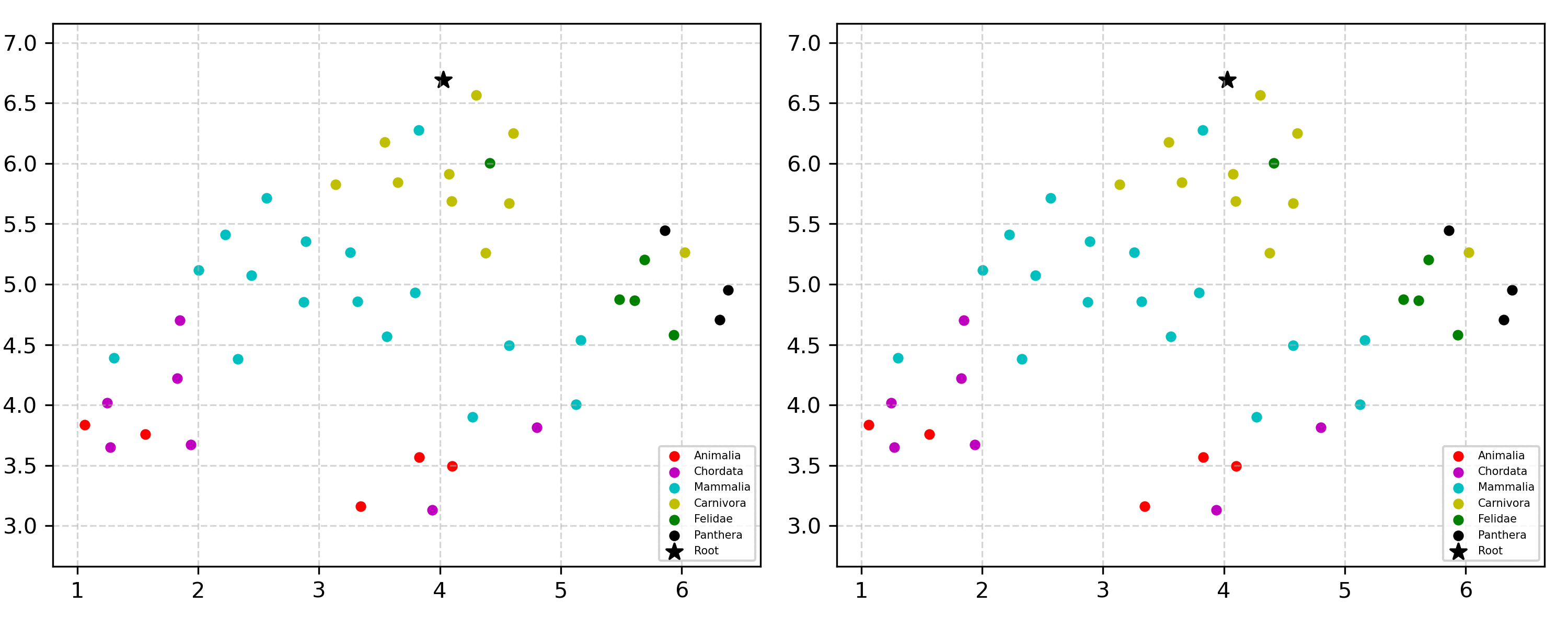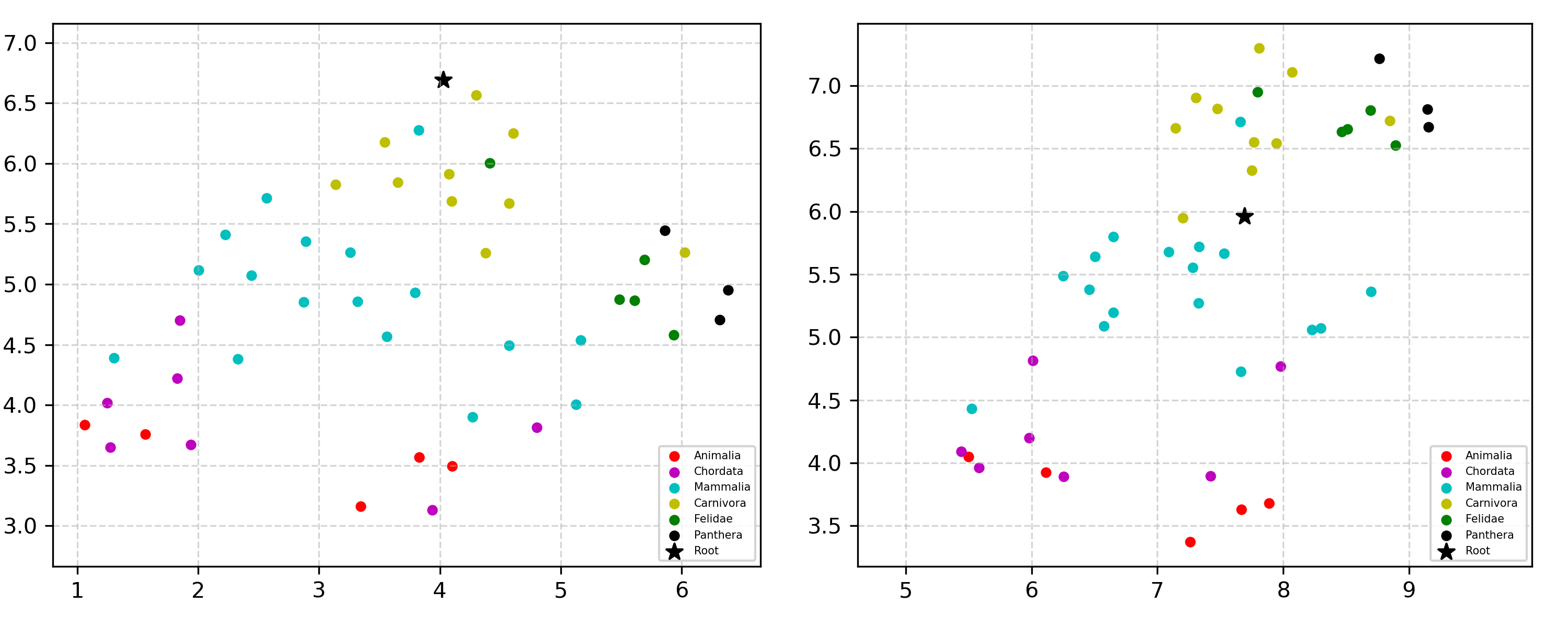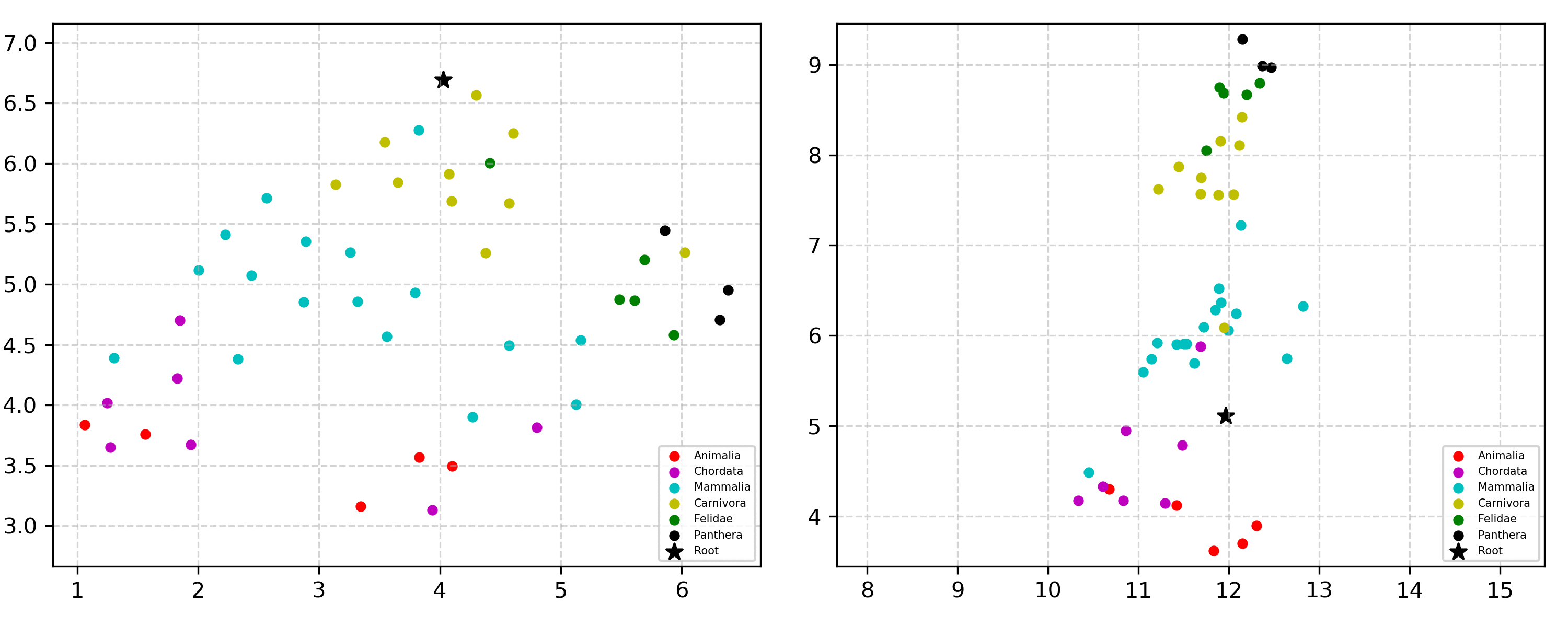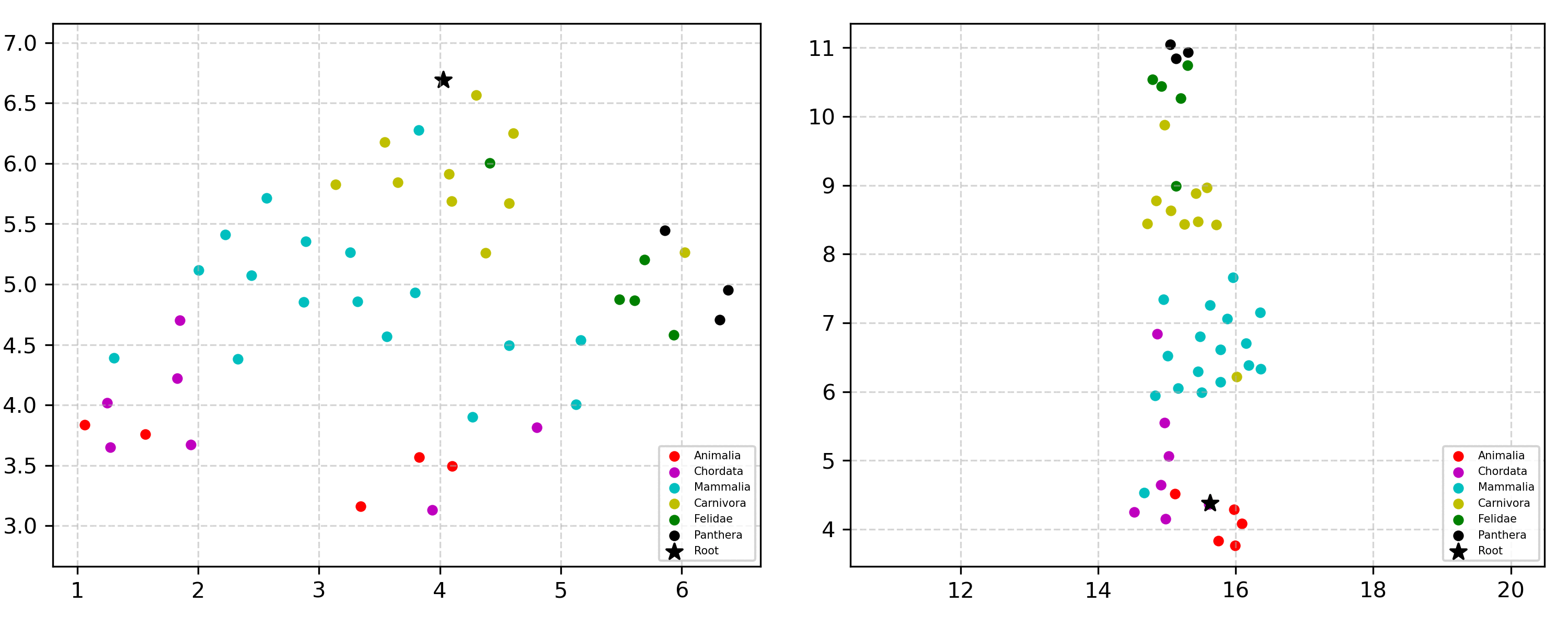
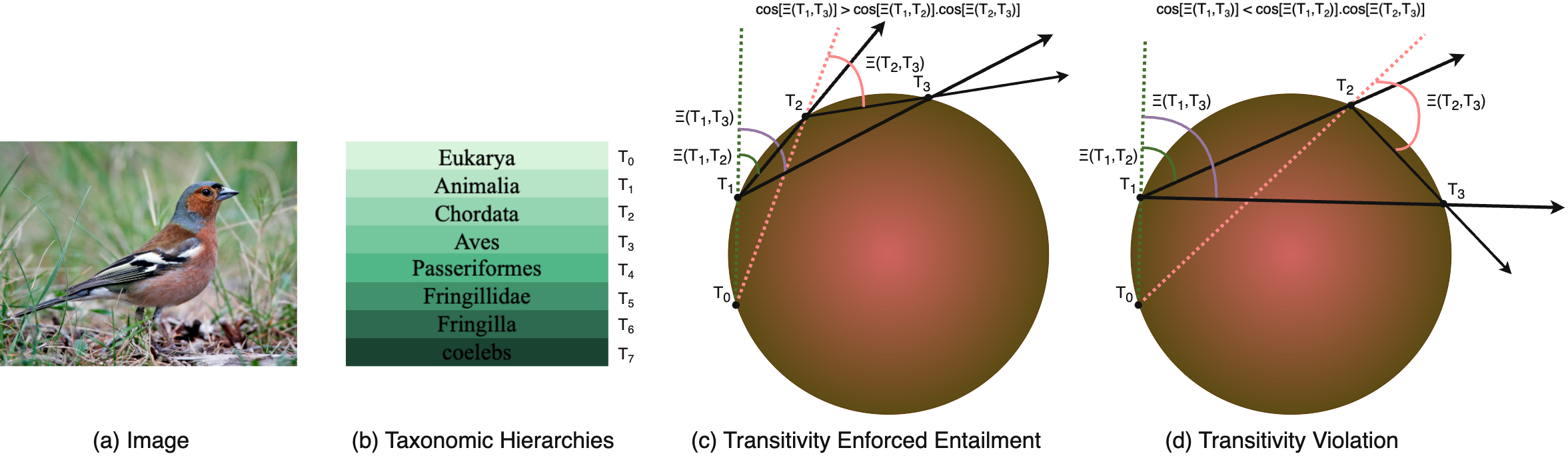
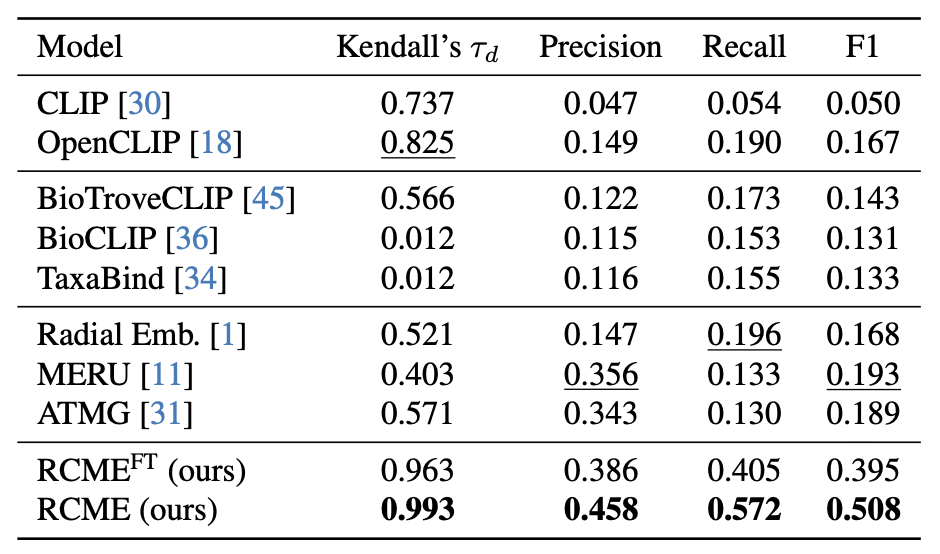
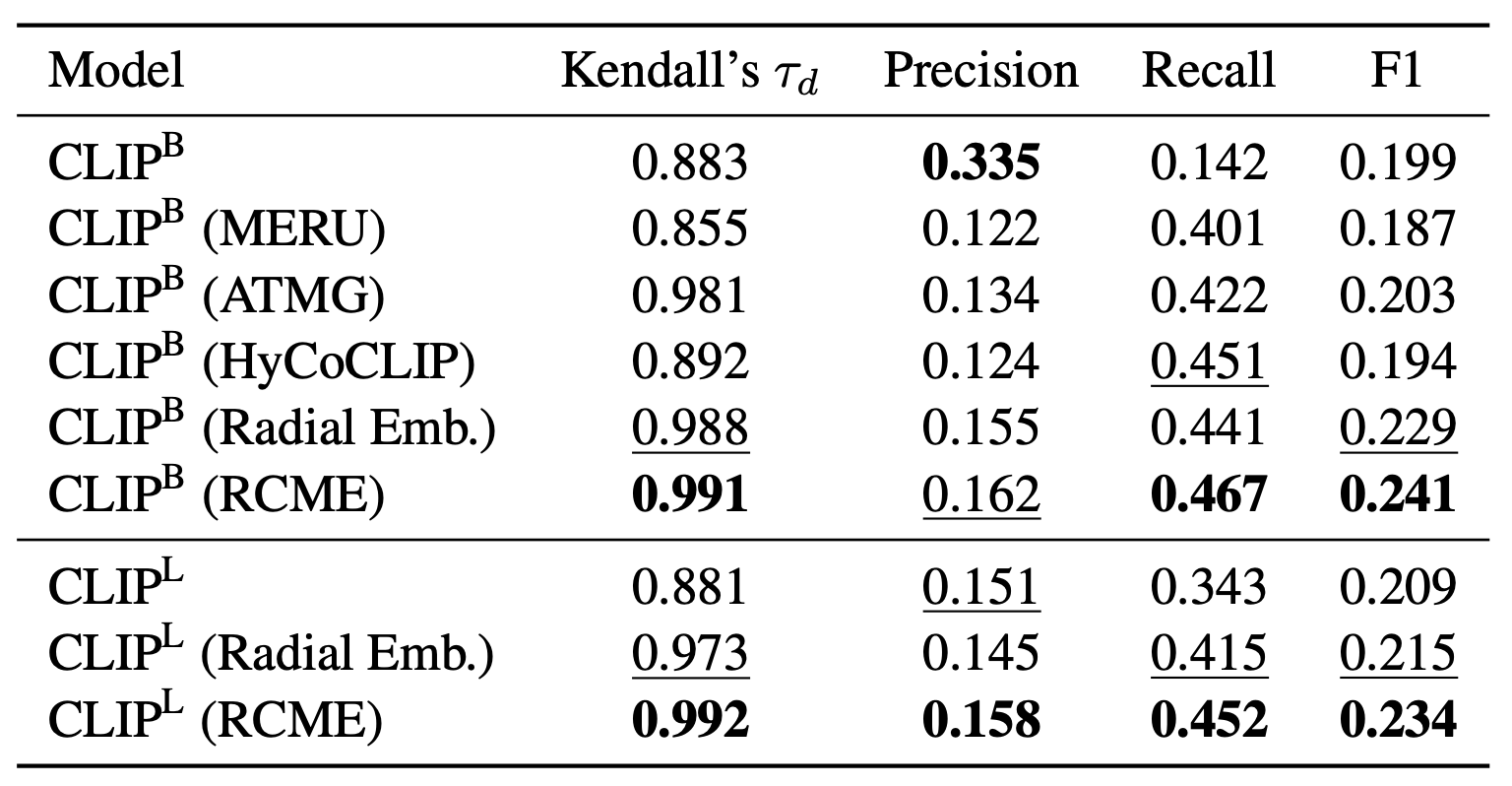
Learning the hierarchical structure of data in vision-language models is a significant challenge. Previous works have attempted to address this challenge by employing entailment learning. However, these approaches fail to model the transitive nature of entailment explicitly, which establishes the relationship between order and semantics within a representation space. In this work, we introduce Radial Cross-Modal Embeddings (RCME), a framework that enables the explicit modeling of transitivity-enforced entailment. Our proposed framework optimizes for the partial order of concepts within vision-language models. By leveraging our framework, we develop a hierarchical vision-language foundation model capable of representing the hierarchy in the Tree of Life. Our experiments on hierarchical species classification and hierarchical retrieval tasks demonstrate the enhanced performance of our models compared to the existing state-of-the-art models.

@inproceedings{sastry2025global,
title={Global and Local Entailment Learning for Natural World Imagery},
author={Sastry, Srikumar and Dhakal, Aayush and Xing, Eric and Khanal, Subash and Jacobs, Nathan},
booktitle={International Conference on Computer Vision},
year={2025},
organization={IEEE/CVF}
}