|
Srikumar Sastry I am a PhD candidate at Washington University in Imaging Science, working in Multimodal Vision Research Laboratory led by Dr. Nathan Jacobs. I have an MS in Geoinformatics from The Faculty ITC, Geoinformation Science and Earth Observation. During my Masters, I was supervised by Dr. Mariana Belgiu and Dr. Raian Vargas Maretto, and worked on developing active learning methods in remote sensing. Email / CV / Scholar / Github / Academic Service |

|
News
|
ResearchI am interested in multimodal learning, computer vision, remote sensing and generative/bayesian modeling. My work involves multimodal representation learning and fusing heterogeneous multimodal data for remote sensing applications involving fine-grained classification, satellite image synthesis, species distribution modeling, change detection, and land cover mapping. |

|
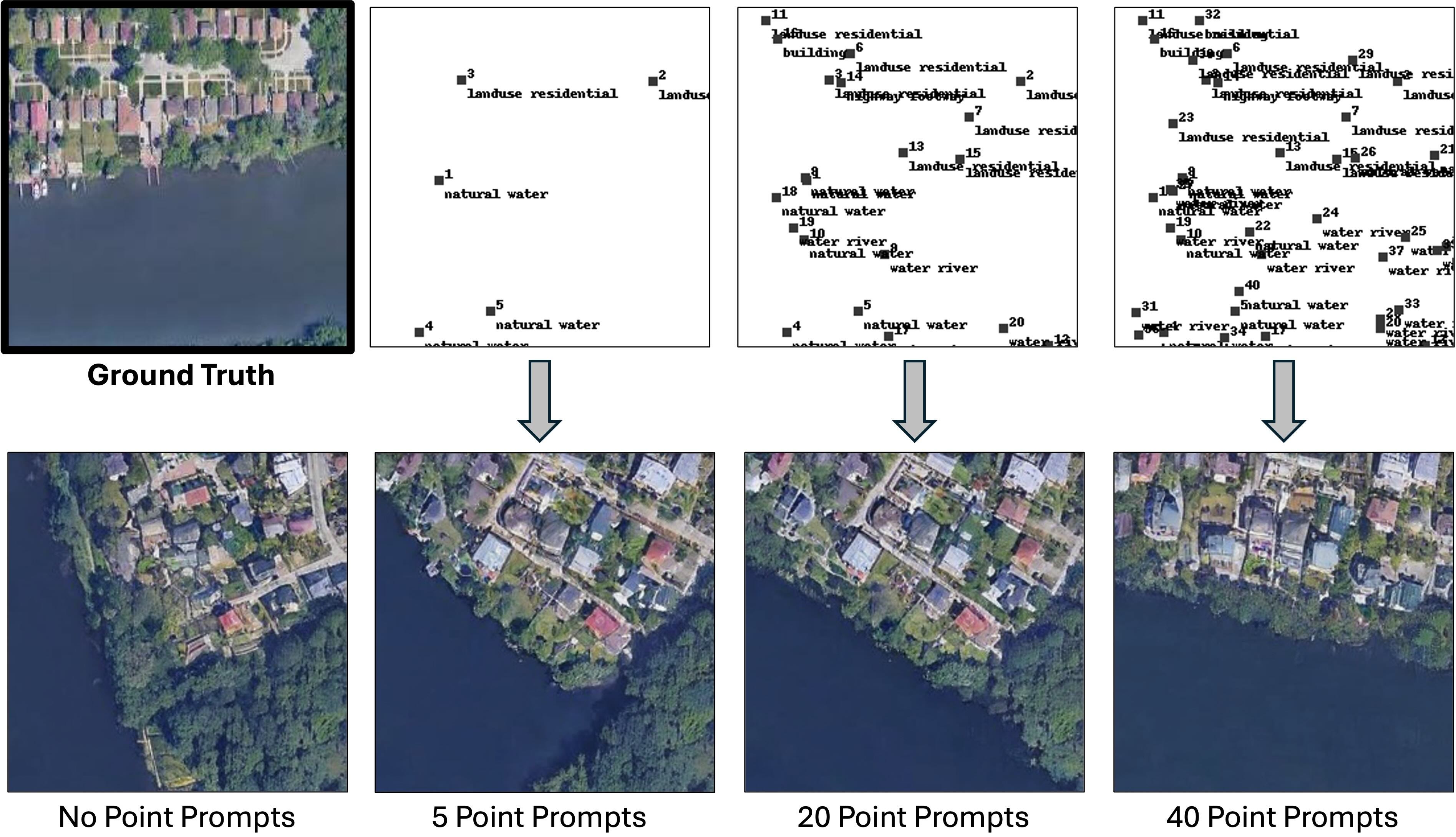
TerraDiT-Ω: Unified Spatial
Control for Satellite Image
Synthesis with Any Geospatial
Primitive
Brian Wei*, Srikumar Sastry*, Dan Cher*, Eric Xing, Nathan Jacobs ECCV, 2026 project page / github / arXiv We propose TerraDiT-Ω, a unified spatial control framework for satellite image generation that directly leverages native geospatial primitives—including points, bounding boxes, polylines, and polygons—enabling controllable synthesis across varying annotation budgets while remaining compatible with GeoAI workflows. TerraDiT-Ω introduces Geometry-Aware Local Attention to inject explicit geometric cues into the generation process, achieving state-of-the-art performance across conditioning formats and providing a versatile foundation for controllable data augmentation in diverse remote sensing tasks. |
|
TerraDiT: Point-Conditioned
Diffusion Transformer for
Satellite Image Synthesis
Srikumar Sastry*, Dan Cher*, Brian Wei*, Aayush Dhakal, Subash Khanal, Dev Gupta, Nathan Jacobs TerraBytes (ECCV), 2026 (Oral Presentation) project page / github / arXiv We propose TerraDiT, a diffusion transformer for text-to-satellite image generation with point-based control, enabling semantically rich and spatially precise generation using only point locations and textual descriptions instead of dense pixel-level maps. TerraDiT introduces an adaptive local attention mechanism to incorporate point queries effectively, achieving state-of-the-art performance while providing a flexible, annotation-efficient, and computationally simple framework for controllable satellite image synthesis. |
|
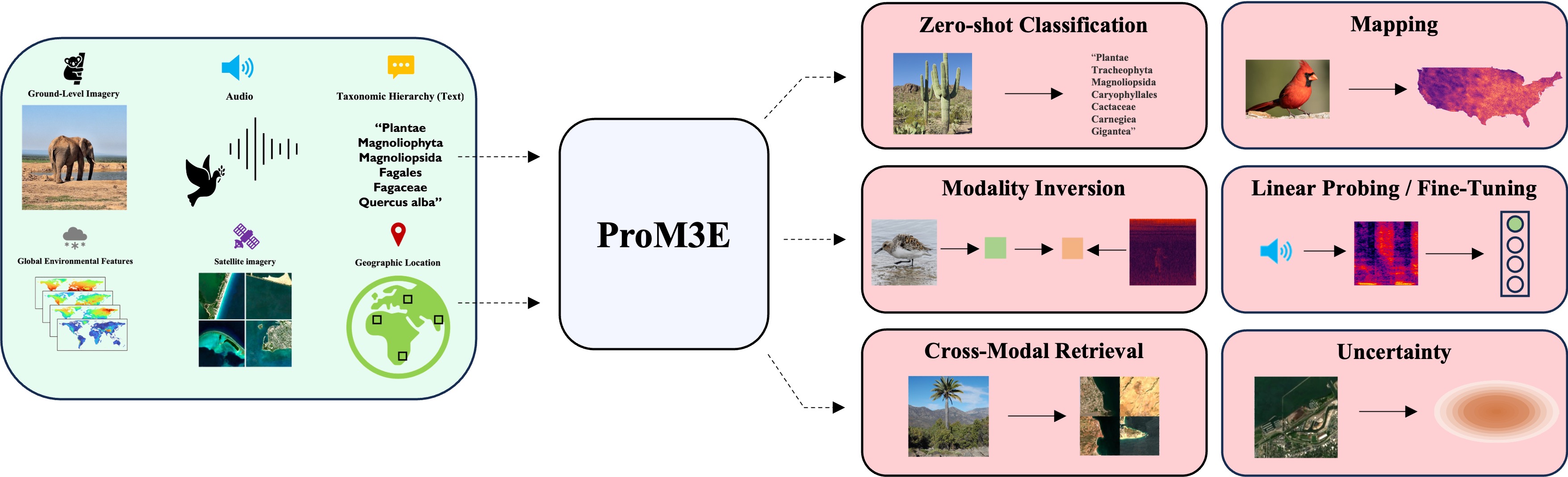
ProM3E: Probabilistic Masked
MultiModal Embedding Model for
Ecology
Srikumar Sastry, Subash Khanal, Aayush Dhakal, Jiayu Lin, Dan Cher, Phoenix Jarosz, Nathan Jacobs CVPR, 2026 project page / github / arXiv We introduce ProM3E, a probabilistic masked multimodal embedding model that enables any-to-any modality generation, fusion feasibility analysis, and superior cross-modal retrieval and representation learning through masked modality reconstruction in the embedding space. |
|
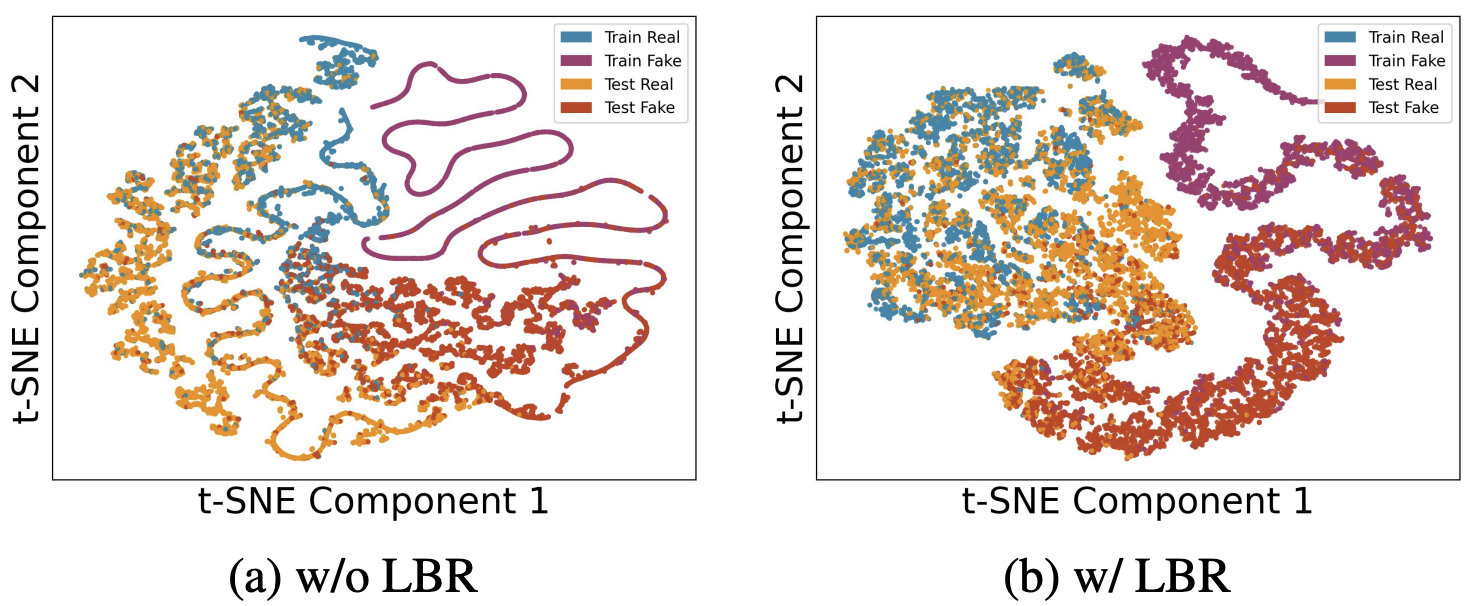
SimLBR: Learning to Detect Fake
Images by Learning to Detect
Real Images
Aayush Dhakal, Subash Khanal, Srikumar Sastry, Jacob Arndt, Philipe Ambrozio Dias, Dalton Lunga, Nathan Jacobs CVPR, 2026 project page / github / arXiv We propose SimLBR, a simple and efficient fake image detection framework that learns a tight decision boundary around the real image distribution and treats fake images as a sink class, improving robustness under distribution shift. |
|
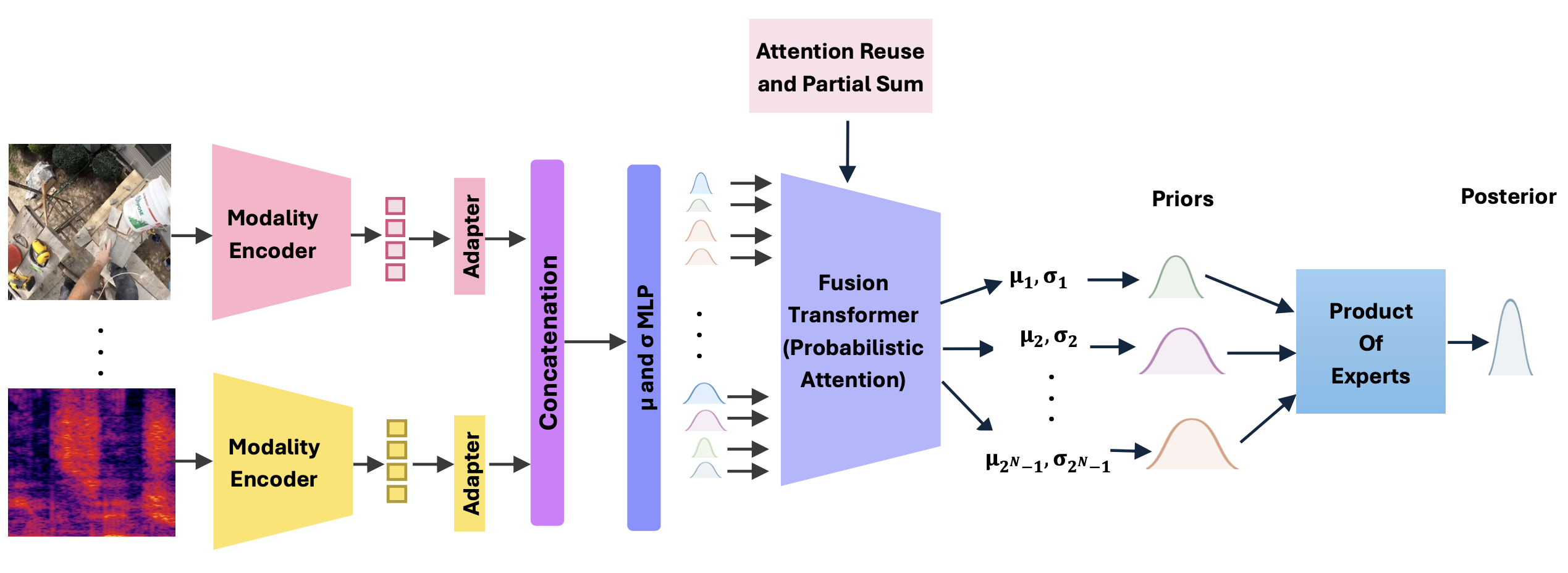
Probabilistic Multimodal
Learning with Bayesian
Disagreements
Srikumar Sastry, Anustup Choudhury, Pavani Madala, Guan-Ming Su Multimodal Learning and Applications (CVPR), 2026 project page / github / arXiv We propose PMBD, a probabilistic multimodal learning framework that addresses multiplicity, misalignment, and noise in multimodal data using a novel Bayesian Disagreement loss and Product of Experts fusion. It also introduces an efficient attention reuse algorithm and a Probabilistic Attention mechanism (PMBD-PA) for fine-grained token-level uncertainty quantification. |
|
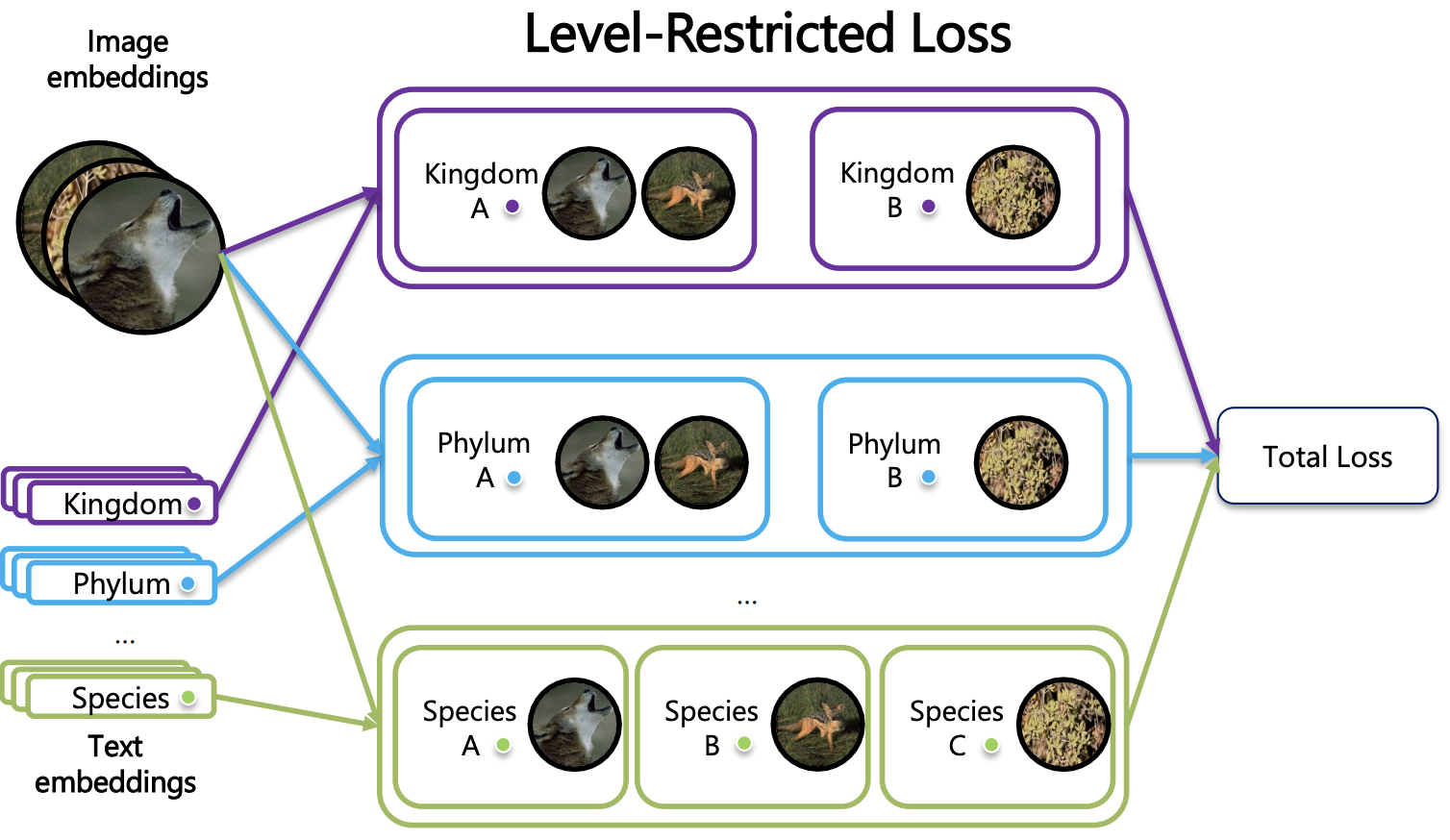
Beyond Flat Labels:
Level-Restricted Contrastive
Learning for Hierarchical
Fine-Grained Vision
Classification
Zhiyuan Tao, Srikumar Sastry, Matthew Thompson, Elizabeth Campolongo, Net Zhang, Ziheng Zhang, Hilmar Lapp, Yu Su, Tanya Berger-Wolf, Nathan Jacobs, Wei-Lun Chao, Jianyang Gu Fine-Grained Visual Categorization, FGVC (CVPR), 2026 (Non-Archival Track) project page / github / arXiv We propose a hierarchical multimodal contrastive learning framework that avoids false negatives across taxonomic levels by restricting comparisons within the same level. Combined with a group-balanced optimization strategy, the method substantially improves hierarchical consistency and zero-shot classification accuracy from coarse to fine granularity. |
|
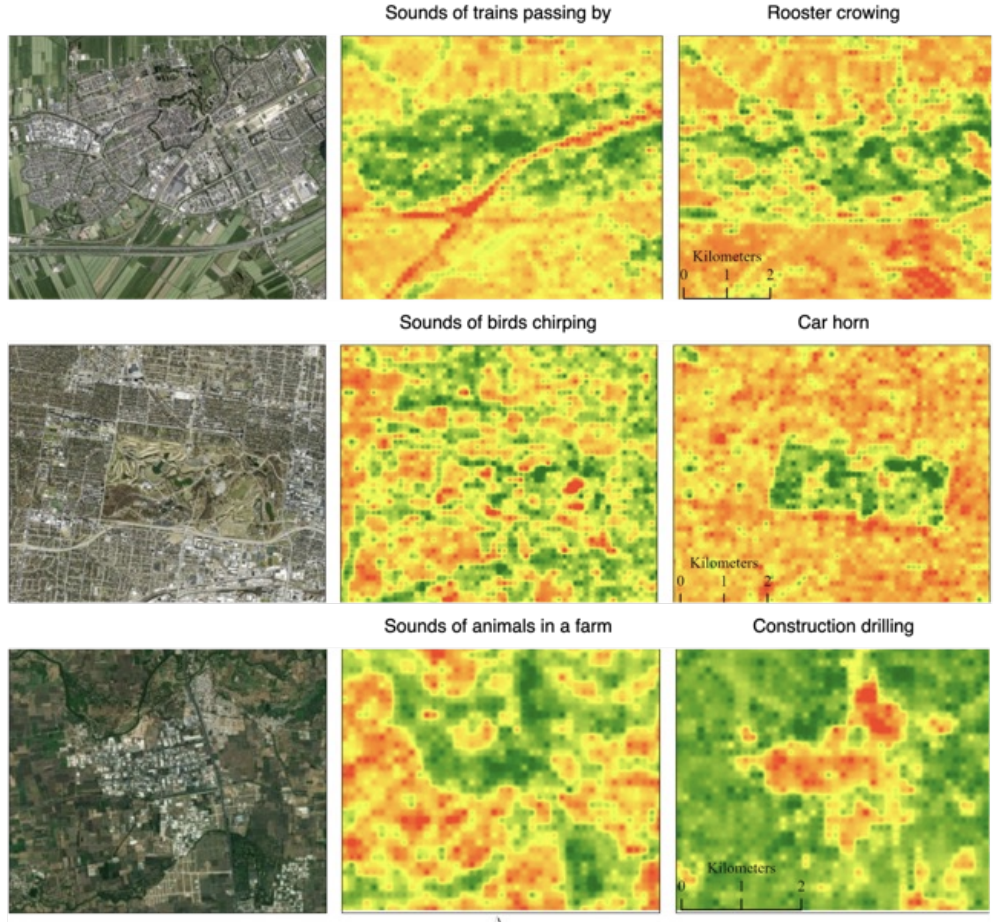
Sat2Sound: A Unified Framework
for Zero-Shot Soundscape
Mapping
Subash Khanal, Srikumar Sastry, Aayush Dhakal, Adeel Ahmad, Nathan Jacobs Earthvision (CVPR), 2026 project page / github / arXiv A state-of-the-art soundscape mapping framework that leverages a Vision-Language Model (VLM) to enrich the semantic understanding of a location’s soundscape, learns a shared codebook for fine-grained alignment, and enables retrieval-based, location-conditioned soundscape generation. |
|
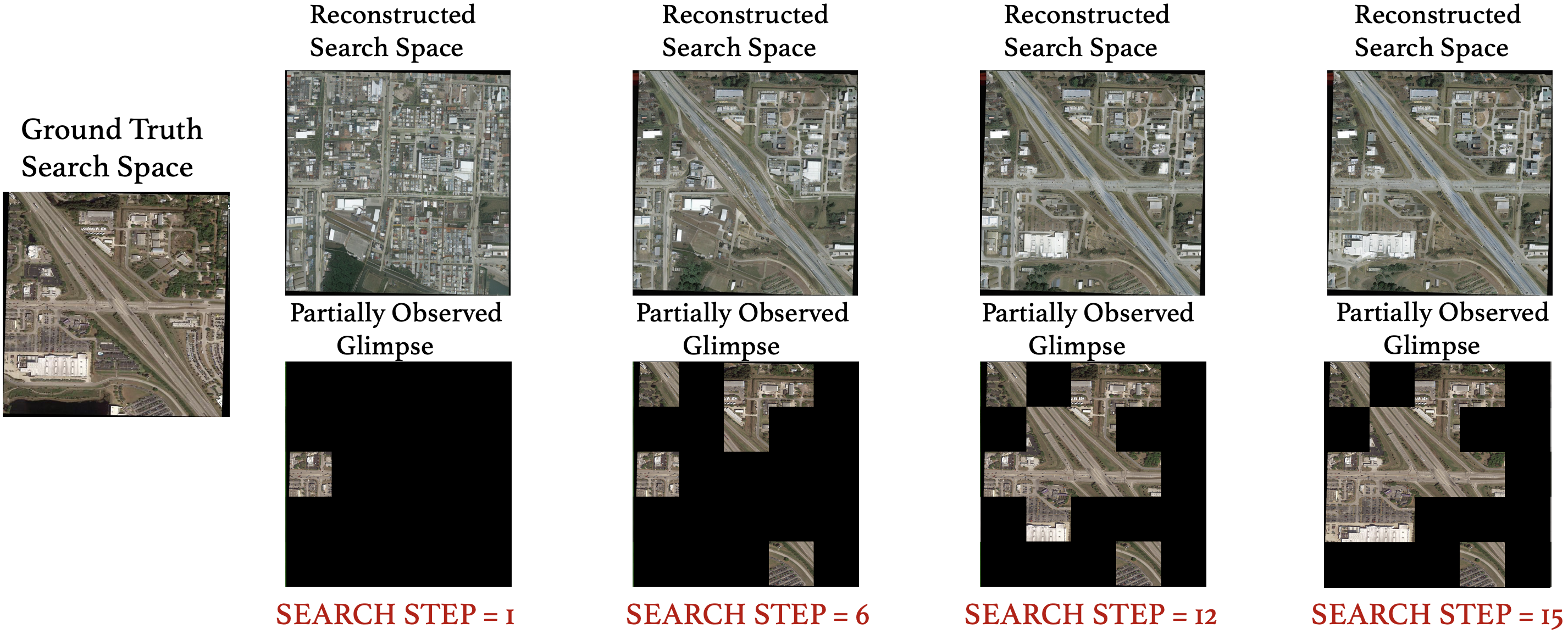
DiffVAS: Diffusion-Guided
Visual Active Search in
Partially Observable
Environments
Anindya Sarkar*, Srikumar Sastry*, Aleksis Pirinen, Nathan Jacobs, Yevgeniy Vorobeychik AAMAS, 2026 (Oral Presentation) project page / github / arXiv We consider the task of active geo-localization (AGL) in which an agent uses a sequence of visual cues observed during aerial navigation to find a target specified through multiple possible modalities. |
|
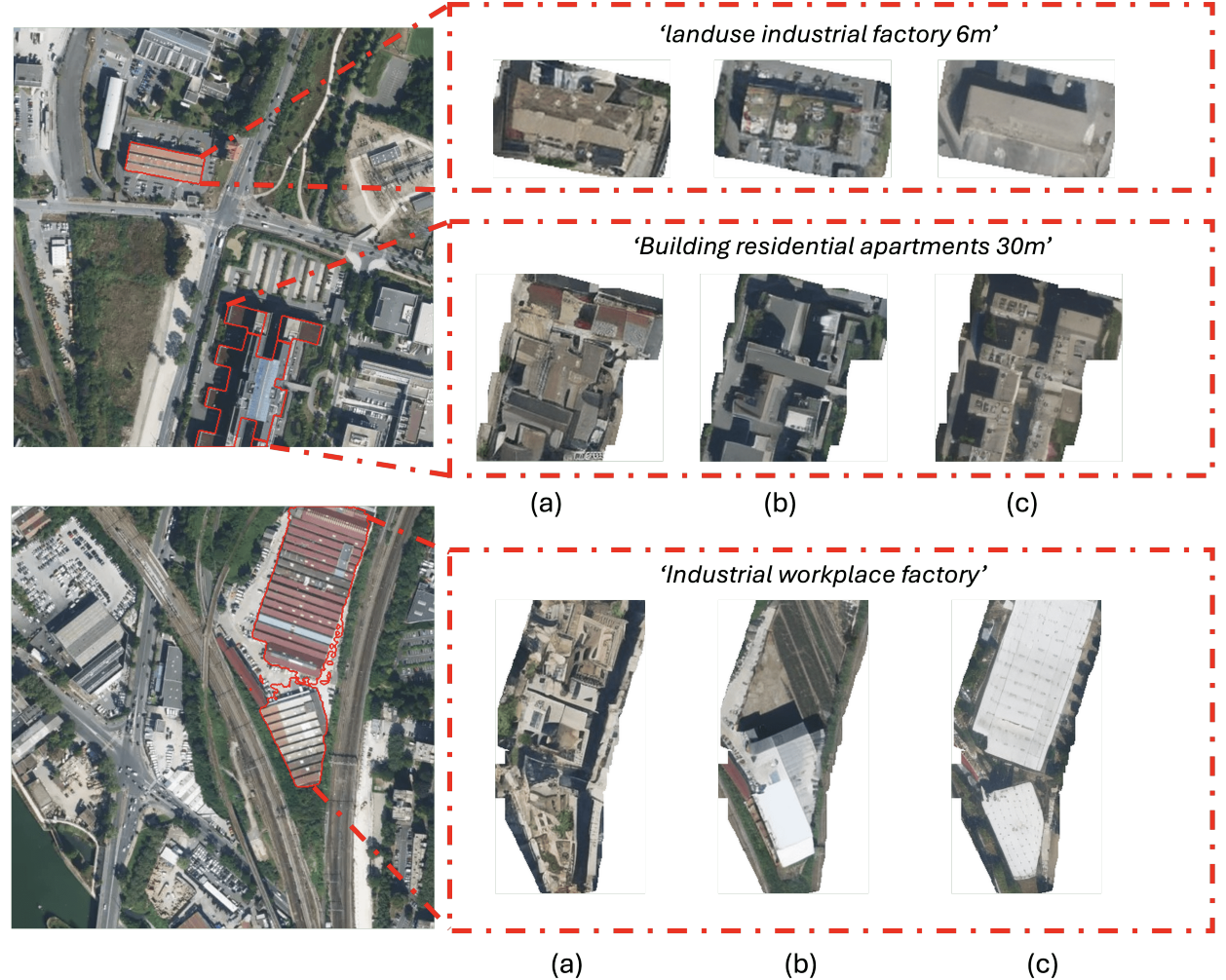
VectorSynth: Fine-Grained
Satellite Image Synthesis with
Structured Semantics
Dan Cher*, Brian Wei*, Srikumar Sastry, Nathan Jacobs WACV, 2026 project page / github / arXiv We introduce VectorSynth, a diffusion-based model that generates pixel-accurate satellite imagery from polygonal geographic annotations with semantic attributes, enabling spatially grounded, geometry- and language-guided image synthesis and editing with superior semantic and structural fidelity. |

|
Global and Local Entailment
Learning for Natural World
Imagery
Srikumar Sastry, Aayush Dhakal, Eric Xing, Subash Khanal, Nathan Jacobs ICCV, 2025 project page / github / arXiv In this work, we introduce Radial Cross-Modal Embeddings (RCME), a framework that enables the explicit modeling of transitivity-enforced entailment. Our proposed framework optimizes for the partial order of concepts within vision-language models. |
|
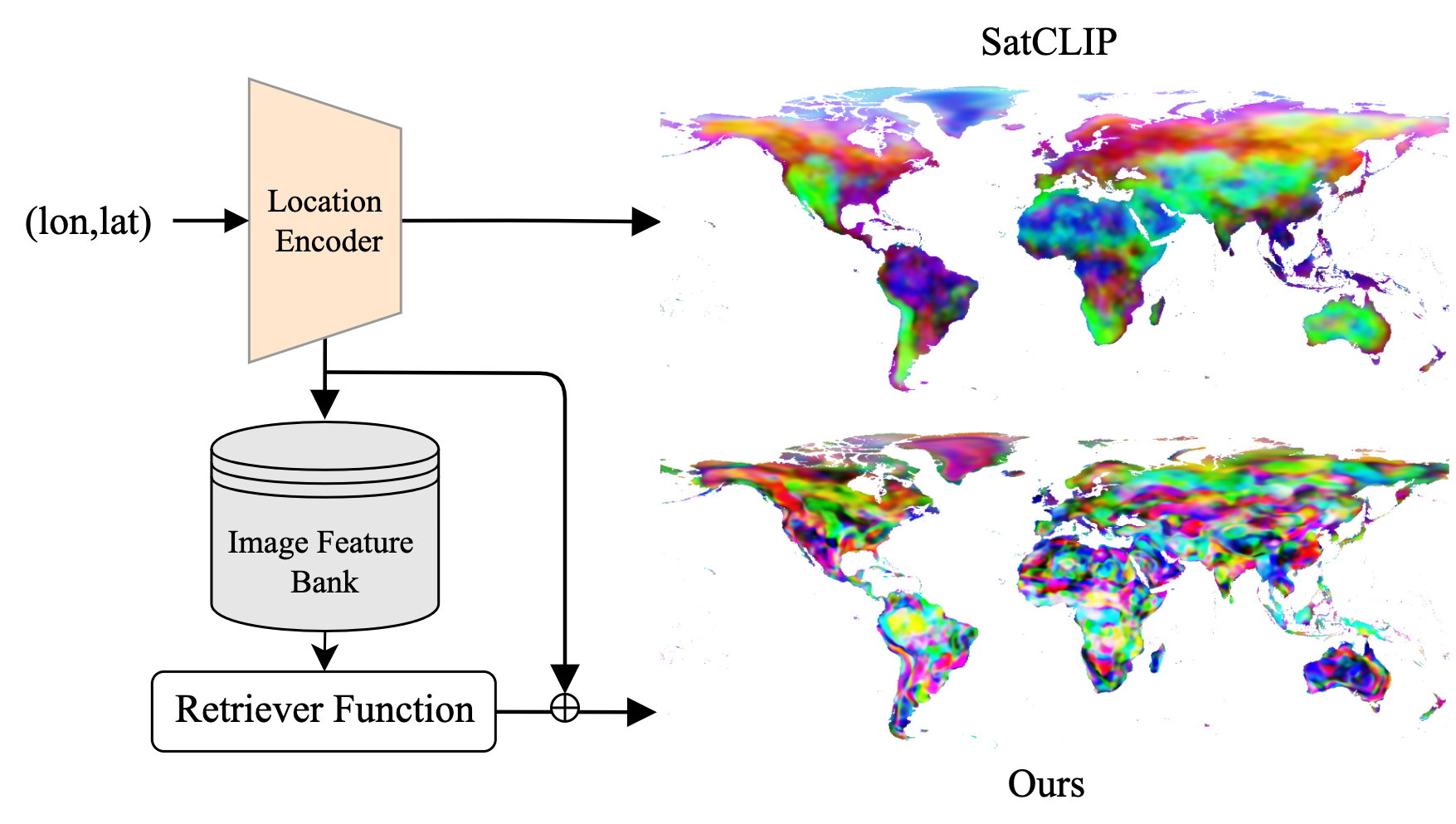
RANGE: Retrieval Augmented
Neural Fields for
Multi-Resolution
Geo-Embeddings
Aayush Dhakal, Srikumar Sastry, Subash Khanal, Eric Xing, Adeel Ahmad, Nathan Jacobs CVPR, 2025 project page / github / arXiv We propose a novel retrieval-augmented strategy called RANGE, to fully capture the important visual features necessary to represent a geographic location. |
|
|
TaxaBind: A Unified Embedding
Space for Ecological
Applications
Srikumar Sastry, Subash Khanal, Aayush Dhakal, Adeel Ahmad, Nathan Jacobs WACV, 2025 (Oral Presentation, Top 8%) project page / github / arXiv / press TaxaBind is a suite of multimodal models useful for downstream ecological tasks covering six modalities: ground-level image, geographic location, satellite image, text, audio, and environmental features. |
|
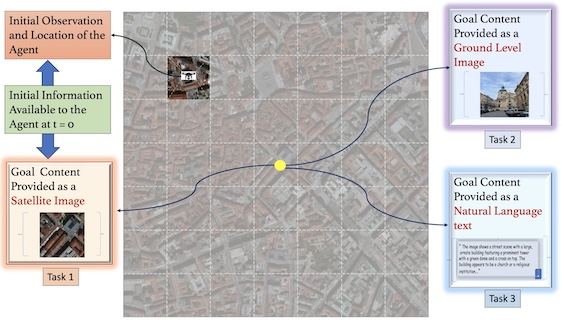
GOMAA-Geo: GOal Modality
Agnostic Active Geo-localization
Anindya Sarkar*, Srikumar Sastry*, Aleksis Pirinen, Chonjie Zhang, Nathan Jacobs, Yevgeniy Vorobeychik NeurIPS, 2024 project page / github / arXiv We consider the task of active geo-localization (AGL) in which an agent uses a sequence of visual cues observed during aerial navigation to find a target specified through multiple possible modalities. |
|
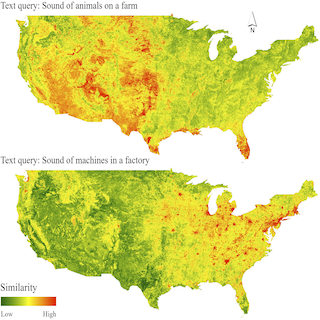
PSM: Learning Probabilistic
Embeddings for Multi-scale
Zero-shot Soundscape
Mapping
Subash Khanal, Eric Xing, Srikumar Sastry, Aayush Dhakal, Zhexiao Xiong, Adeel Ahmad, Nathan Jacobs ACM Multimedia, 2024 project page / github / arXiv A soundscape is defined by the acoustic environment a person perceives at a location. In this work, we propose a framework for mapping soundscapes across the Earth. |

|
GEOBIND: Binding Text, Image,
and Audio through Satellite
Images
Aayush Dhakal, Subash Khanal, Srikumar Sastry, Adeel Ahmad, Nathan Jacobs IGARSS, 2024 (Oral Presentation) project page / github / arXiv In this work, we present a deep-learning model, GeoBind, that can infer about multiple modalities, specifically text, image, and audio, from satellite imagery of a location. To do this, we use satellite images as the binding element and contrastively align all other modalities to the satellite image data. |

|
GeoSynth: Contextually-Aware
High-Resolution Satellite Image
Synthesis
Srikumar Sastry, Subash Khanal, Aayush Dhakal, Nathan Jacobs Earthvision (CVPR), 2024 project page / github / arXiv / press We present GeoSynth, a model for synthesizing satellite images with global style and image-driven layout control. The global style control is via textual prompts or geographic location. These enable the specification of scene semantics or regional appearance respectively, and can be used together. |
|
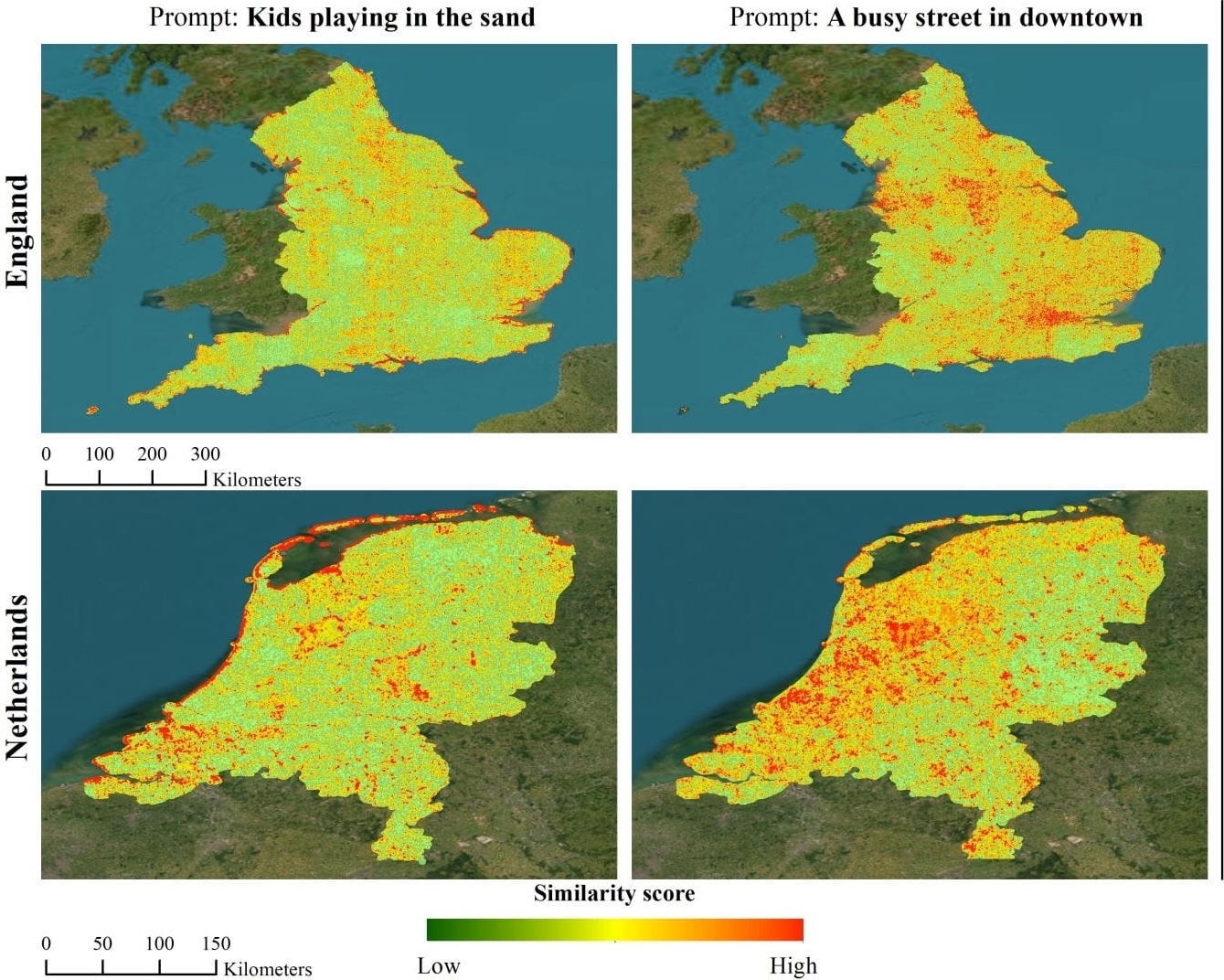
Sat2Cap: Mapping Fine-Grained
Textual Descriptions from
Satellite Images
Aayush Dhakal, Adeel Ahmad, Subash Khanal, Srikumar Sastry, Hannah Kerner, Nathan Jacobs Earthvision (CVPR), 2024 (Oral Presentation, Best Paper Award) project page / github / arXiv / press We propose a weakly supervised approach for creating maps using free-form textual descriptions. We refer to this work of creating textual maps as zero-shot mapping. |

|
ClimSatDiff: Synthesizing the
Earth's Surface Conditioned on
Climatic Variables using
Diffusion Models
Srikumar Sastry, Adeel Ahmad, Aayush Dhakal, Subash Khanal, Eric Xing, Nathan Jacobs American Geophysical Union (AGU), 2024 project page In this work, we present a model that can synthesize the visual appearance of the Earth's surface conditioned on climate and time. We use PRISM and temporally rich cloud-free Sentinel-2 Level 2A and LandSat-8 for this study. |
|
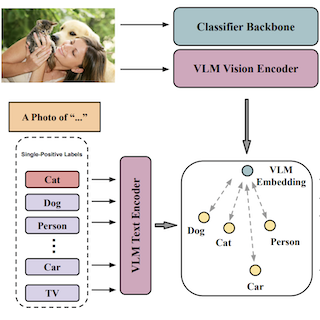
Vision-Language Pseudo-Labels
for Single-Positive Multi-Label
Learning
Xin Xing, Zhexiao Zhang, Abby Stylianou, Srikumar Sastry, Liyu Gong, Nathan Jacobs LIMIT (CVPR), 2024 project page / github / arXiv We propose a novel model called Vision-Language Pseudo-Labeling (VLPL) which uses a vision-language model to suggest strong positive and negative pseudo-labels. |
|
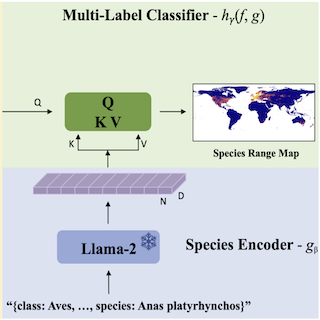
LD-SDM: Language-Driven
Hierarchical Species
Distribution Modeling
Srikumar Sastry, Xin Xing, Aayush Dhakal, Subash Khanal, Adeel Ahmad, Nathan Jacobs Computer Vision for Ecology Workshop (CV4E), ICCV, 2025 arXiv We focus on the problem of species distribution modeling using global-scale presence-only data. To capture a stronger implicit relationship between species, we encode the taxonomic hierarchy of species using a large language model. |

|
BirdSAT: Cross-View Contrastive
Masked Autoencoders for Bird
Species Classification and
Mapping
Srikumar Sastry, Subash Khanal, Aayush Dhakal, Di Huang, Nathan Jacobs WACV, 2024 project page / github / arXiv We propose a metadata-aware self-supervised learning (SSL) framework useful for fine-grained classification and ecological mapping of bird species around the world. Our framework unifies two SSL strategies: Contrastive Learning (CL) and Masked Image Modeling (MIM), while also enriching the embedding space with metadata available with ground-level imagery of birds. |
|
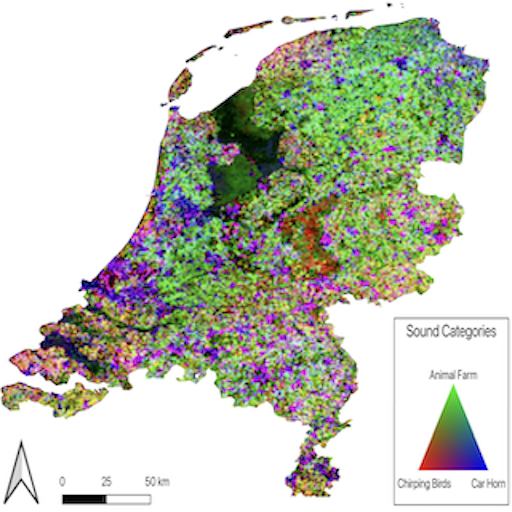
Learning Tri-modal Embeddings
for Zero-Shot Soundscape Mapping
Subash Khanal, Srikumar Sastry, Aayush Dhakal, Nathan Jacobs BMVC, 2023 project page / github / arXiv We focus on the task of soundscape mapping, which involves predicting the most probable sounds that could be perceived at a particular geographic location. We utilise recent state-of-the-art models to encode geotagged audio, a textual description of the audio, and an overhead image of its capture location using contrastive pre-training. |

|
Task Agnostic Cost Prediction
Module for Semantic Labeling in
Active Learning
Srikumar Sastry, Nathan Jacobs, Mariana Belgiu, Raian Vargas Maretto IGARSS, 2023 (Oral Presentation) We consider the problem of cost effective active learning for semantic segmentation, which aims at reducing the efforts of semantically annotating images. |
Miscellanea |
|
Service 
|
Reviewer, NeurIPS
[2024
(Top Reviewer, Top 8%), 2025, 2026]
Reviewer, ECCV [2024, 2026 (Outstanding Reviewer, Top 6%)] Reviewer, ICML [2025, 2026 (Silver Reviewer, Top 50%)] Reviewer, CVPR [2025, 2026] Reviewer, ICLR [2025, 2026] Reviewer, AAAI [2026, 2027] Reviewer, Transactions on Machine Learning Research (TMLR) [2025] Reviewer, ACM Multimedia [2025] Reviewer, AISTATS [2025] Reviewer, ISPRS (VLM For RS) [2024] Reviewer, Earthvision Workshop(CVPR) [2025] Reviewer, CV4EO Workshop (WACV) [2024,2025] |
|
Teaching 
|
Center
for Environment
Undergraduate Research Mentor,
Summer 2024
Center for Environment Undergraduate Research Mentor, Summer 2023 Graduate Student Instructor, CSE 559A Spring 2023 |
|
Awesome Huggingface Demos 
|
List of my favorite huggingface demos |